
Every year, S&P 500 companies could save up to $920 billion if they completely transition into AI. — “AI Adoption and the Future of Work” by Morgan Stanley
And no, that’s not a typo! Companies could accumulate savings up to a whopping $1 trillion and the majority of those lies in a place most teams can’t see clearly: the chaotic, unstructured documents that actually run the business (contracts, medical charts, invoices, emails, lab reports, PDFs, scanned forms, and more).
Meanwhile, 65% of organizations report they’ve adopted generative AI into their daily workflow—nearly double from last year. All this reveals that the race to turn documents into data is very much on.
Now here’s the kicker: roughly four out of five bytes your company stores are unstructured data, and that pile is only growing with every passing second. If you’ve ever wondered why “”we have the data”” rarely means “”we can use the data”,” that’s the reason. Intelligent data extraction (IDE) is how AI transforms that sprawl into clean, structured, analysis-ready facts; consistently, at scale, and with traceability.
Below is a practical guide on how AI extracts data from complex documents: what it is, how it works behind-the-scenes, where it shines (and stumbles), and how to implement it without compromising your existing roadmap. We will also analyze how solutions like DeepKnit AI approach high-stakes domains (e.g. medical records) with the rigor they require.
Intelligent Data Extraction: What Is Involved
- IDE utilizes advanced OCR, Natural Language Processing (NLP), advanced Large Language Models (LLMs) and AI-powered document analysis to convert unstructured content (PDFs, images, handwritten notes) into structured data (tables, JSON, knowledge graphs, infographics).
- The best systems always bring together established rules + machine learning + LLMs, secured by domain ontologies and validation checks.
- Human-in-the-loop AI review, tangible quality metrics and diligent governance are indispensable; especially for regulated industries.
- Begin with a lighter load (one document type, one business outcome), check for ROI and then generalize the pipeline.
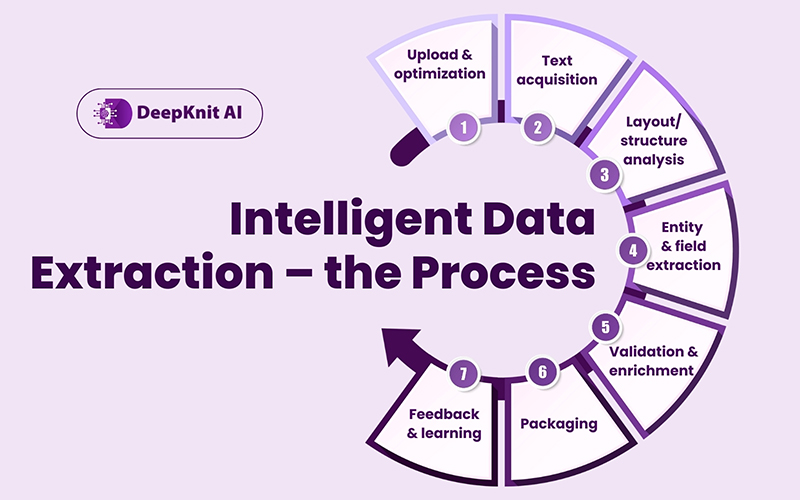
Intelligent Data Extraction – the Process
Intelligent data extraction is the end-to-end process of identifying, reading, understanding, and structuring information from unstructured or semi-structured documents so downstream systems (ERPs, CRMs, case management tools, BI dashboards, RAG pipelines) can use it reliably.
Think of it as a multi-stage assembly line:
- Upload & optimization (accept any format: PDF, TIFF, email body, attachments, images; adjust resolution, orientation, color space).
- Text acquisition (OCR for scans, native text from digital PDFs, speech-to-text for audio if needed).
- Layout/structure analysis (detect pages, sections, tables, headers/footers, columns, key-value pairs, signatures, stamps).
- Entity & field extraction (names, dates, policy numbers, ICD-10 codes, dosage, prices, totals, clauses).
- Validation & enrichment (cross-checks, business rules, referential data lookups, ontology mapping).
- Packaging (emit JSON/CSV, push to a database or message bus, or insert into a knowledge graph).
- Feedback & learning (human review, active learning, error analytics to continuously improve models).
This highlights why AI for unstructured document processing is rapidly growing to be an inevitable necessity for modern enterprises.
The AI Magic: How Modern Systems “Understand” Documents
Sometimes, it’s hard to fathom the working and sheer power of of document processing with AI. It is not just a single technology, but a seamless conglomeration of various automation technologies, working together to generate the desired output.
- OCR
- Deep learning OCR takes care of skew, noise, and mixed scripts; it recognizes text in stamps, watermarks, and low-contrast scans.
- Layout-aware OCR preserves reading order and coordinates, which are vital for table extraction, two-column reports, and labels aligned with values.
- Document layout understanding (DLU)
- AI models precisely interpret the visual structure: paragraph vs. table cell vs. sidebar vs. footnote.
- Table detection and reconstruction turns gridlines or whitespace into structured rows/columns (with headers and merged cells).
- NLP and domain semantics
- NER (Named Entity Recognition) finds people, organizations, meds, CPT/ICD codes, claim IDs, clause types.
- Relation extraction links entities: “Medication X — 50 mg — BID — start date 2024-09-12.”
- Ontology grounding maps raw text to canonical codes (e.g., “heart attack” → ICD-10 I21).
- Large Language Models (LLMs)
- Instruction-tuned LLMs are great at interpreting varied phrasing across templates.
- Use constrained decoding (JSON schemas), function calling, and toolformer-style retrieval to keep outputs structured and consistent.
- RAG (Retrieval-Augmented Generation): fetch relevant snippets from the document (and approved knowledge bases) before extraction, to improve accuracy and traceability.
- Hybrids beat purists
- Rules & regex still shine for stable patterns (invoice totals, MRNs, claim numbers).
- ML & LLMs handle the long tail and messy edge cases.
- Voting/ensemble strategies (rule + model + LLM) improve precision and reduce hallucinations.
- Validation
- Cross-field constraints (“Discharge Date ≥ Admission Date”).
- Type checks & ranges (dates, NPI formats, currency).
- External lookups (provider registry, formulary).
- Confidence thresholds & escalation to human review.
From PDF to Payload: The Extraction Process
- Pre-processing
- Deskewing, denoising, orientation correction, DPI normalization.
- Redaction zones (e.g., automatically blur PII in previews) without harming the raw text capture.
- OCR & Text Fusion
- Prefer native text if available; fall back to OCR.
- Merge outputs with bounding boxes to support provenance: each extracted field links to its exact coordinates.
- Block Segmentation & Table Parsing
- Identify titles, sections, bullet lists, figures, footnotes; detect multi-column flows.
- Rebuild tables with header inference and column typing.
- Field Extraction with LLM-assisted Templates
- Prompt LLMs with document metadata (“Document type: Discharge Summary”), target schema, and few-shot examples.
- Use JSON-schema constrained generation so outputs never drift.
- Normalization & Enrichment
- Standardize units (mg vs. milligrams), normalize dates, map clinical terms to codes.
- Add semantic types (e.g. “medication.name”, “medication.dose”).
- Quality Check
- Run business rules and anomaly detection; flag low confidence for review.
- Log per-field confidence and validation results.
- Output Generation
- Emit clean JSON to your queue/database.
- Persist provenance (doc ID, page, bbox) for auditability.
Human-in-the-Loop (HITL): The Better Half of IDE Success
The team of AI and humans is not a compromise, but a winning formula in not just controlling the process, but also ensuring 100% accuracy.
- Triage: Auto-approve “green” items; route “amber” to quick review; “red” to specialist.
- Explainability: Show the snippet, highlight the source region, display validation failures.
- Continuous Learning: Corrections feed a labeled data store; schedule retraining on high-impact fields.
Ensuring Data Governance, Privacy, and Compliance
Data security is paramount for regulated industries (healthcare, financial services, public sector). Here’s how to ensure complete confidentiality:
- PII/PHI Handling: Encryption at rest and in transit, access controls, field-level redaction in UI.
- Auditability: Keep a provenance graph linking every extracted value to its page and coordinates.
- Model Governance: Version control for models/prompts; approval workflows; rollback capability.
- Compliance: HIPAA/PHI safeguards for healthcare; SOC 2 controls; regional data residency where applicable.
- Dataset Security: Prevent data leakage into training sets where consent isn’t covered; isolate customer prompts and outputs.
IDE: High Impact Use Cases
- Healthcare & Life Sciences: Intake packets, referral letters, discharge summaries, lab reports, operative notes. Extract diagnoses, meds, vitals, allergies, timelines, and adverse events—then compile case summaries.
- Insurance: FNOLs, adjuster notes, claims forms, repair estimates, policy endorsements.
- Financial Services: KYC packets, bank statements, loan docs, trade confirms, compliance disclosures.
- Legal & Compliance: Contract clause extraction (renewals, indemnities), e-discovery prioritization, privilege screening.
- Supply Chain & Operations: Bills of lading, PoDs, packing lists, quality certificates, purchase orders.
- Customer Operations: Emails and forms triage, sentiment, intent, key fields; automated ticket routing.
- Public Sector: Permits, benefit applications, land records, court documents.
ROI: Modeling Benefits
When you model ROI, make sure to consider both hard and soft benefits:
- Hard: Minimized manual processing hours, lower rework, fewer compliance penalties, faster reimbursements.
- Soft: Higher CSAT, shorter time-to-answer, improved analyst focus, faster onboarding of new document types. Imagine this scenario: if manual processing an invoice averages around $16 including rework, and you handle 10,000 invoices/year, that’s an approximate $160k in direct handling cost. If IDE reduces manual intervention by 60–80%, the savings are massive, before you even count faster cycles or fewer disputes. Additionally, error rate assumptions matter. Even a 3–5% manual entry error rate each time, becomes costly at volume (chargebacks, interest, clawbacks). IDE’s validations and cross-checks can eliminate error-driven costs materially.
Insource vs Outsource: A Pragmatic Decision Tree
Build IDE if:
- You have unique compliance constraints or proprietary ontologies.
- Your documents are hyper-specialized, and off-the-shelf accuracy is inadequate.
- You can dedicate a persistent team for models, prompts, data ops, and MLOps.
Buy IDE if:
- You need broad coverage quickly for common doc types.
- You want SLAs, audit trails, and integrations out of the box.
- You prefer predictable TCO and frequent vendor-driven upgrades.
Go hybrid:
- Choose the best vendor platform for OCR/layout and general extraction, with custom LLM prompts, validation rules, and ontologies layered on top.
Future of Intelligent Data Extraction: What’s In the Scene (and What’s the Hype)
- Multimodal Understanding: Modern models will parse text, layout and images jointly—think of charts, stamps, signatures, even embedded photos.
- Agents with Tools: Autonomous agents call OCR, retrieval, calculators, and validators in sequence, and document every step for audit.
- Structured Generation: Native JSON outputs with schemas and function calls; no more post-hoc parsing.
- On-device / On-prem LLMs: Sensitive workloads avoid external calls without needing to compromise accuracy.
- Domain-specific Copilots: Targeted assistants for claims adjusters, clinical coders, underwriters—each tuned to its ontology.
- Synthetic Data for Special Cases: Generate edge-case layouts to improve recall without hunting for scarce real docs.
Bonus: Procurement Checklist (use this to compare vendors)
- Accuracy Assessment: Ask for published per-field precision/recall with confidence intervals.
- Provenance: Do you get coordinates and source snippets for every extracted field?
- Controls for Hallucination: JSON schemas, validation hooks, and rejection rules.
- Domain Ontologies: Native support for your codes/terms (ICD-10, SNOMED, CPT; NAICS; standard clauses).
- HITL UX: One-click corrections, keyboard flows, and bulk approvals.
- Learning Loop: Does the AI model learn from corrections automatically?
- Security & Compliance: SOC 2, HIPAA capabilities, data residency, tenant isolation.
- MLOps & Governance: Versioned prompts/models, rollback, AB testing, drift detection alerts.
- Integration: Webhooks, queues, APIs; schema registry; real-time and batch.
- TCO & Roadmap: Pricing transparency (pages, fields, users), SLAs, and an upgrade cadence that fits your needs.
Final Thoughts
The opportunity isn’t just reading documents faster—it’s reasoning over them: accurately connecting fragments across sources, verifying against policies, and delivering answers in the exact shape your enterprise expects. Intelligent data extraction is how you operationalize that leap, from document clutter to data clarity.
Get Accurate, Structured Insights from Messy Documents
DeepKnit AI enhances intelligent data extraction for clinical and high-stakes domains
Schedule a Demo